

Distributed Locking - Part 2
Different Mechanism for use cases

Why Do We Need Distributed Locks?
Picture a distributed system as a team of collaborators working on a project. Each member has a role to play, and sometimes, their tasks might overlap. To prevent confusion, duplication of effort, or errors, a mechanism is needed to control when and how team members access shared tools, files, or data.
Similarly, in a distributed system, various nodes or processes might need to access the same resource concurrently. Without proper synchronization, this could lead to race conditions — a situation where the final outcome depends on the order of execution. This can result in data corruption, inaccurate results, or even system crashes.
In the event that multiple instances of a microservice attempt to execute the same operation concurrently, we could potentially encounter issues such as data loss, data corruption, or data inconsistency. To illustrate, consider a scenario involving an inventory system wherein numerous users are endeavoring to buy the same item. As parallel procedures endeavor to modify the inventory concurrently, it could result in over-selling, given that the product’s availability is not accurately maintained.
As a business impact Overselling of products leads to a rise in cancellations, diminished customer experience (Cx), culminating in customer attrition and decreased customer retention
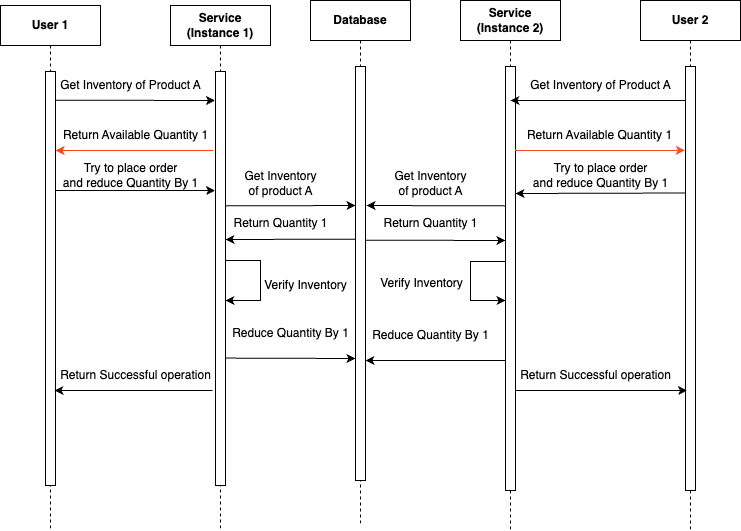
In the sequence diagram provided above, it is depicted that both User 1 and User 2 simultaneously discover that there is a single unit of product A available in the inventory. Subsequently, they both attempt to initiate an order for the product at the same time. Due to the absence of a locking mechanism, both deduction operations are successful without any hindrance, resulting in the placement of their respective orders.
How Do Distributed Locks Work?
Distributed locks implement a simple yet effective concept. When a node or process wants to access a resource, it must request a lock. If the lock is available, the requesting node gains exclusive access to the resource, ensuring that no other node can interfere. Once the task is completed, the lock is released, allowing other nodes to access the resource.
Think of it as a “one-at-a-time” rule for accessing shared resources. Just like a talking stick in a group discussion ensures that only one person speaks at a time, distributed locks ensure that only one node can access a resource at a given moment.

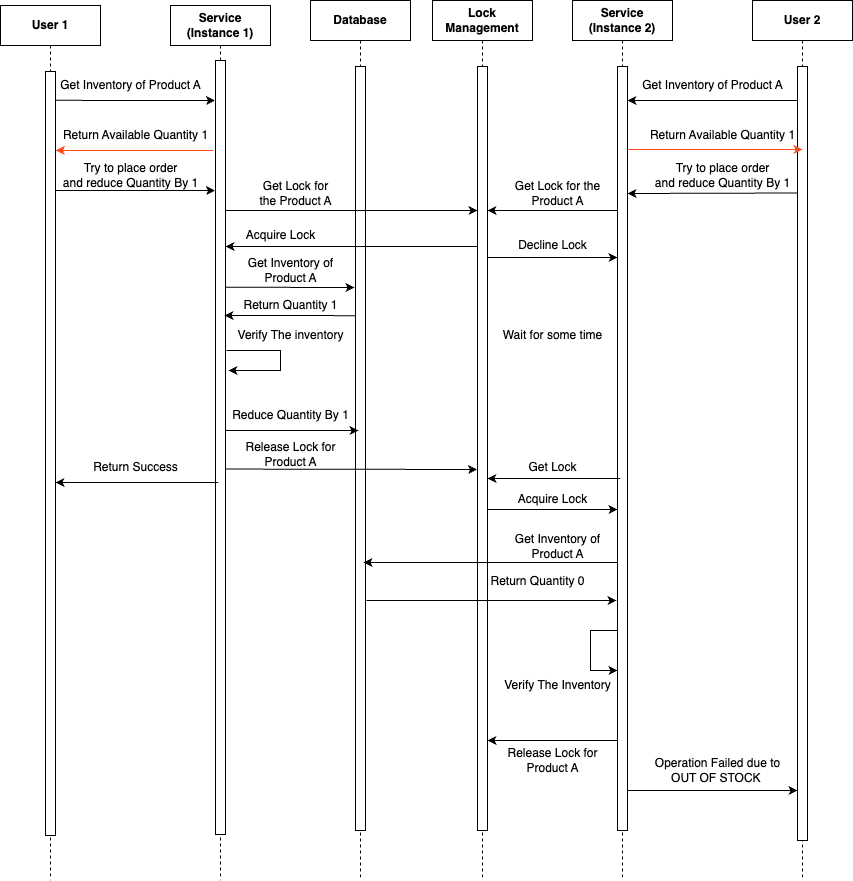
In the sequence diagram provided above, it is illustrated that both User 1 and User 2 simultaneously observe an inventory of one unit for product A. Subsequently, they both make attempts to initiate an order for the product. However, due to the presence of a distributed lock mechanism, User 1’s request to reduce the inventory by one unit is acknowledged. This acknowledgment allows User 1 request to successfully deduct the unit from the inventory, resulting in a successful operation. As a result of this successful deduction, User 1’s order is placed successfully.
Benefits of Distributed Locks
Data Integrity: Distributed locks safeguard data integrity by preventing simultaneous modifications that could lead to corruption.
Resource Utilization: Locks help manage resource utilization effectively, preventing resource hogging and ensuring fair access among nodes.
Concurrency Control: With distributed locks, multiple nodes can work concurrently without stepping on each other’s toes, optimizing system performance.
What are the different mechanisms by which we can achieve distributed locks?
Distributed locks can be achieved through various mechanisms and technologies, each suited for different use cases and requirements. Here are some common approaches to implementing distributed locks:
ZooKeeper: Apache ZooKeeper is a distributed coordination service that can be used for implementing distributed locks. ZooKeeper provides a “sequential” znode feature that allows clients to create ephemeral nodes in a sequential order. By monitoring the sequence of znodes, clients can implement distributed locks. A synthetic code for distributed locks using zookeeper is below.
// connection to zookeeper
ZooKeeper zooKeeper = new ZooKeeper(ZOOKEEPER_SERVER);
var path = "my_path"
// Create a lock node which is automatically deleted by the Zookeeper
// so we use EPHEMERAL SEQUENTIAL
var zNode = zooKeeper.createEphemeralSequentialNode(path+"/lock_");
if( checkIfLockeAquiredFor(zNode)){
// Perform critical section
//delete the node to release the lock
zookeeper.delete(zNode);
} else{
// failed to get the lock
}
function checkIfLockeAquiredFor(var zNode){
var n = 10;
//get all child Nodes in the path
while(n > 0){
var childNodes[] = zookeeper.getChildren(path);
//sort childNode and check if the top child is same as zNode created;
if(childNodes[0] == zNode.getName())
return true;
sleep(1000)
n--;
}
return false;
}
Pros:
Sequential Locks: ZooKeeper can be used to create sequential locks, ensuring fairness in lock acquisition. Processes are granted locks in the order they requested them.
Watch Mechanism: ZooKeeper supports the watch mechanism, allowing clients to receive notifications when lock conditions change. This can simplify coordination between processes.
Ephemeral Nodes: Locks can be implemented as ephemeral znodes (nodes in ZooKeeper’s hierarchical structure). If a client holding a lock crashes, the lock is automatically released when the session expires.
Cons:
Complexity: Implementing distributed locks with ZooKeeper can be complex, especially for developers who are new to the platform. Managing ZooKeeper connections and handling edge cases like network partitions requires careful consideration.
Performance Overhead: ZooKeeper introduces additional network communication and overhead for maintaining consensus, which can impact performance compared to simpler in-memory locking mechanisms.
Scalability Concerns: While ZooKeeper is highly reliable, it can become a scalability bottleneck if used excessively for locking purposes in large-scale systems. It’s essential to use it judiciously.
Operational Complexity: Managing and maintaining a ZooKeeper ensemble (a group of ZooKeeper servers) can be operationally complex. Ensuring high availability and monitoring can require additional effort.
Single Point of Failure (SPOF): The ZooKeeper ensemble itself can be a single point of failure. To ensure high availability, you need to set up ZooKeeper in a fault-tolerant manner.
2. Database-Based Locks: Use a database to manage distributed locks. Create a table dedicated to locks, where each lock corresponds to a row. Acquiring a lock involves inserting a row into the table, while releasing the lock involves deleting the row. Database transactions ensure consistency. However, this method might introduce database contention. A simple example for database-Based locks is given below.
-- Acquire a distributed lock for a specific product's inventory
BEGIN TRANSACTION;
-- Check if the lock is available
SELECT LockStatus FROM Locks WHERE ProductID = specified_product_id;
IF LockStatus = 'available' THEN
-- Set the lock status to 'locked' to prevent other stores from acquiring it
UPDATE Locks SET LockStatus = 'locked' WHERE ProductID = specified_product_id;
-- Perform inventory update
UPDATE Inventory SET Quantity = new_quantity WHERE ProductID = specified_product_id;
-- Release the lock
UPDATE Locks SET LockStatus = 'available' WHERE ProductID = specified_product_id;
COMMIT; -- Commit the transaction
RETURN 'Inventory update successful';
ELSE
ROLLBACK; -- Rollback the transaction
RETURN 'Inventory update failed: Lock not available';
END IF;Pros:
Data Consistency: Database locks help maintain data consistency by preventing conflicting modifications to shared resources. They ensure that only one user or process can modify the data at a time, preventing data corruption or inconsistencies.
Simplicity: Database locks are relatively easy to implement and understand, especially for simple use cases. They utilize the built-in features of database management systems, making it convenient to implement locking mechanisms without extensive custom code.
Transaction Support: Database locks often work in conjunction with transactions, ensuring that the locking and unlocking of resources are done within a transaction boundary. This guarantees atomicity and consistency of lock management.
Cons:
Deadlocks: Poorly managed locks can lead to deadlocks, where multiple processes or threads are waiting for each other to release locks, causing the system to come to a standstill.
Performance Impact: Excessive locking can lead to performance bottlenecks, especially in high-concurrency systems. Lock contention can slow down overall system performance as processes wait for locks to be released.
Complexity with Scale: As the system scales and the number of users or processes increases, managing locks becomes more complex. Coordinating locks across distributed systems or multiple database instances can be challenging.
Blocking: While locks prevent conflicts, they can also introduce blocking. If a process holds a lock while performing a time-consuming operation, other processes that need the same lock will be blocked until the lock is released.
Concurrency Overhead: In some cases, locking might lead to underutilization of resources. For example, if multiple processes could potentially modify different parts of a resource simultaneously without conflict, locking might unnecessarily limit their concurrency.
Lack of Flexibility: Locking can sometimes be overly restrictive, preventing certain types of concurrent access that could actually be safe. This rigidity can lead to suboptimal resource utilization.
Maintenance and Debugging: Debugging and maintaining systems with complex locking mechanisms can be challenging. Incorrectly managed locks can result in hard-to-diagnose issues like data corruption or performance degradation.
3. Redis: Redis, an in-memory data store, offers support for distributed locks through its “SETNX” (set if not exist) and “EXPIRE” commands. When a client sets a key with a specific expiration time, it acquires the lock. Other clients trying to set the same key will fail if the key already exists.
Redis redis = new Redis(redisHost, redisPort)
var uniqueKey = "someReferenceKey"
var lockAquired = redis.aquireLock(uniqueKey,<expire time>);
if(lockAquired ){
//perform critical operations;
redis.delele(uniqueKey);
}
Pros:
Ease of Use: Redis distributed lock libraries like Redisson provide a high-level API that simplifies the process of acquiring and releasing locks. Developers can easily integrate distributed locks into their applications without dealing with low-level synchronization mechanisms.
Scalability: Redis is designed for high availability and supports clustering and replication. This makes it suitable for building distributed systems where locks need to be coordinated across multiple nodes.
Lease Management: Many Redis distributed lock implementations support automatic lock renewal to prevent locks from expiring prematurely due to long-running processes.
Fairness: Some distributed lock libraries offer fairness features, ensuring that the lock is acquired in the order requests are made, preventing starvation and ensuring that all competing processes have a chance to acquire the lock.
Cons:
Single Point of Failure: If your Redis instance becomes unavailable or experiences issues, it can impact the entire application’s ability to acquire locks. It’s important to ensure Redis’s availability and redundancy.
when we use multiple Redis clusters for distributed locks then it complicate things by introducing slower communication between clusters, confusion in managing locks across different places, challenges in making sure everyone agrees on lock usage, potential problems when clusters experience issues, increased complexity in managing and testing, and a greater risk of issues like deadlocks due to the distributed nature of the setup.
As we chart the path to optimizing our application in the face of increasing traffic and a multitude of critical operations, Redis emerges as our steadfast ally. With its exceptional speed and seamless integration into our existing infrastructure, Redis takes center stage as our preferred choice for distributed locking. This decision not only ensures swift and efficient lock management but also allows us to leverage our pre-existing Redis setup, sparing us the complexities of ZooKeeper implementation. Redis aligns seamlessly with our goals, affording us the opportunity to allocate our resources where they matter most: delivering exceptional user experiences.